この記事にはアフィリエイトリンクが含まれる場合があります。

GoogleのGemini APIは、テキスト、画像、音声、動画を扱えるマルチモーダルAIをPythonから利用できるAPIです。2026年5月時点の公式SDKはgoogle-genaiに統合され、旧google-generativeaiからの移行が進んでいます。本記事では、新しいgoogle-genai SDKを前提に、APIキー取得から関数呼び出し、グラウンディング、構造化出力まで実践的に解説します。
料金やモデル仕様はGemini API公式ドキュメントとPricingを参照しています。
Gemini APIとは(2026年5月時点)
Gemini APIは、Google AI StudioまたはVertex AI経由で提供されるLLM APIです。個人開発やプロトタイプはGoogle AI Studioの無料枠から始められ、本番運用や企業要件があるならVertex AI経由に切り替えるという二段構えの設計になっています。
マルチモーダル対応が広く、テキストに加えて画像、PDF、音声、動画を入力として受け取れます。Google検索によるグラウンディング、Code Execution、JSON構造化出力、Function calling(Tool使用)といった機能を、SDK経由でシンプルに呼び出せます。
2026年5月時点のモデルと料金
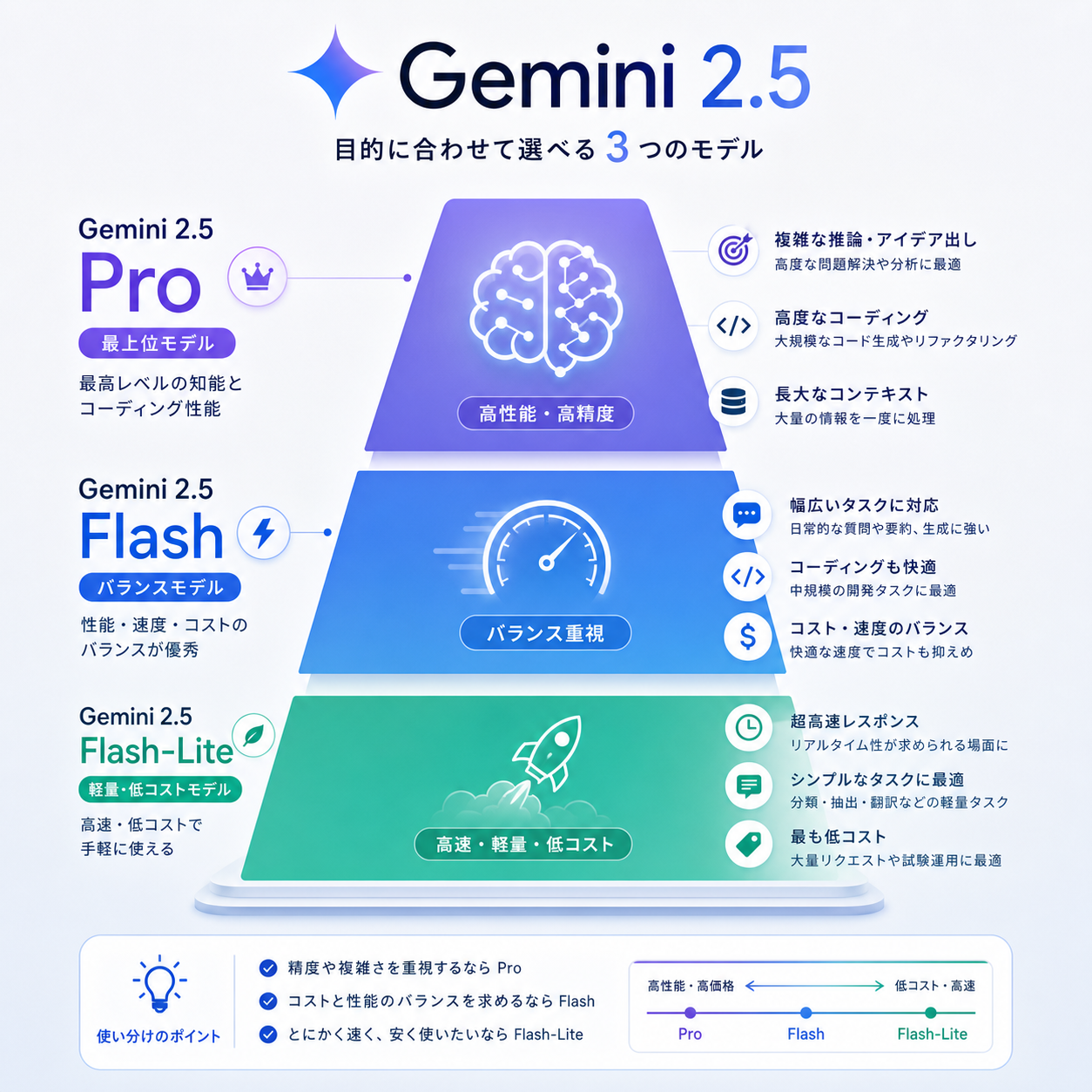
2026年5月時点の主力はGemini 2.5シリーズで、Pro / Flash / Flash-Liteの3モデル構成です。最大コンテキストはProとFlashが1M tokens、Flash-Liteも1M tokens対応で、用途に応じて速度・コスト・推論能力のバランスを選びます。
| モデル | API ID | 強み | 典型用途 |
|---|---|---|---|
| Gemini 2.5 Pro | gemini-2.5-pro | 最高品質、長文推論、マルチモーダル | 分析、設計、高品質生成 |
| Gemini 2.5 Flash | gemini-2.5-flash | 速度とコストのバランス | 一般的なチャット、要約、生成 |
| Gemini 2.5 Flash-Lite | gemini-2.5-flash-lite | 最安、高スループット | 分類、軽量タスク、大量バッチ |
2026年5月時点の概算単価は、Pro入力$1.25・出力$10 / MTok(200kまで)、Flash入力$0.30・出力$2.50 / MTok前後、Flash-Lite入力$0.10・出力$0.40 / MTok前後です。具体値は変動するため、本番設計時には必ず公式Pricingを確認してください。
APIキー取得とSDKインストール
個人開発であればGoogle AI Studioが最短ルートです。Google AI StudioにGoogleアカウントでログインし、左メニューの「Get API key」からキーを発行します。発行したキーは環境変数GEMINI_API_KEYに保存し、ソースコードに直書きしないでください。
# macOS / Linux
export GEMINI_API_KEY="AIza..."
# Windows PowerShell
$env:GEMINI_API_KEY="AIza..."SDKは新しいgoogle-genaiを入れます。旧google-generativeaiを使っている既存プロジェクトは、移行を検討してください。
python -m pip install -U google-genai最小コード:generate_content
クライアントを作ってclient.models.generate_content()を呼ぶのが基本パターンです。APIキーはos.environ["GEMINI_API_KEY"]を自動で読み込みます。
from google import genai
client = genai.Client() # GEMINI_API_KEY を環境変数から自動取得
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Pythonで簡単な電卓関数を書いてください。",
)
print(response.text)応答テキストはresponse.textで取り出せます。トークン消費はresponse.usage_metadataに入っており、入力・出力・キャッシュ読み取りの内訳を取得できます。コスト管理ではこの値をログに残しておくと安心です。
システム指示と生成パラメータ
システム指示やtemperatureなどの生成パラメータはconfigで渡します。
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="このコードをレビューしてください。\n\ndef add(a,b):\n return a+b",
config=types.GenerateContentConfig(
system_instruction="あなたはPythonコードレビューを行うシニアエンジニアです。",
temperature=0.2,
max_output_tokens=1024,
),
)
print(response.text)temperatureは0に近いほど決定的、1に近いほど多様な出力になります。コードレビューやJSON出力では低め、ブレストや創作では高めが目安です。
マルチターンチャット
会話履歴を保持したチャットには、chatsクライアントを使うと便利です。履歴管理をSDKが代行してくれます。
chat = client.chats.create(model="gemini-2.5-flash")
r1 = chat.send_message("Python学習のロードマップを教えて。")
print(r1.text)
r2 = chat.send_message("そのロードマップの第1段階を1日30分で進める計画にして。")
print(r2.text)履歴はchat.get_history()で取り出せます。長期セッションでコストを抑えたい場合は、後述するキャッシュやモデルをgemini-2.5-flash-liteに切り替えるなどの工夫が効きます。
ストリーミング応答
チャットUIで生成中の文字を逐次表示したい場合はgenerate_content_stream()を使います。
for chunk in client.models.generate_content_stream(
model="gemini-2.5-flash",
contents="2026年のAI市場の動向を300字でまとめて。",
):
print(chunk.text, end="", flush=True)応答全体を待たずに少しずつ画面に出せるので、UXが大きく改善します。長文タスクではタイムアウト対策にもなります。
Function calling(Tools)
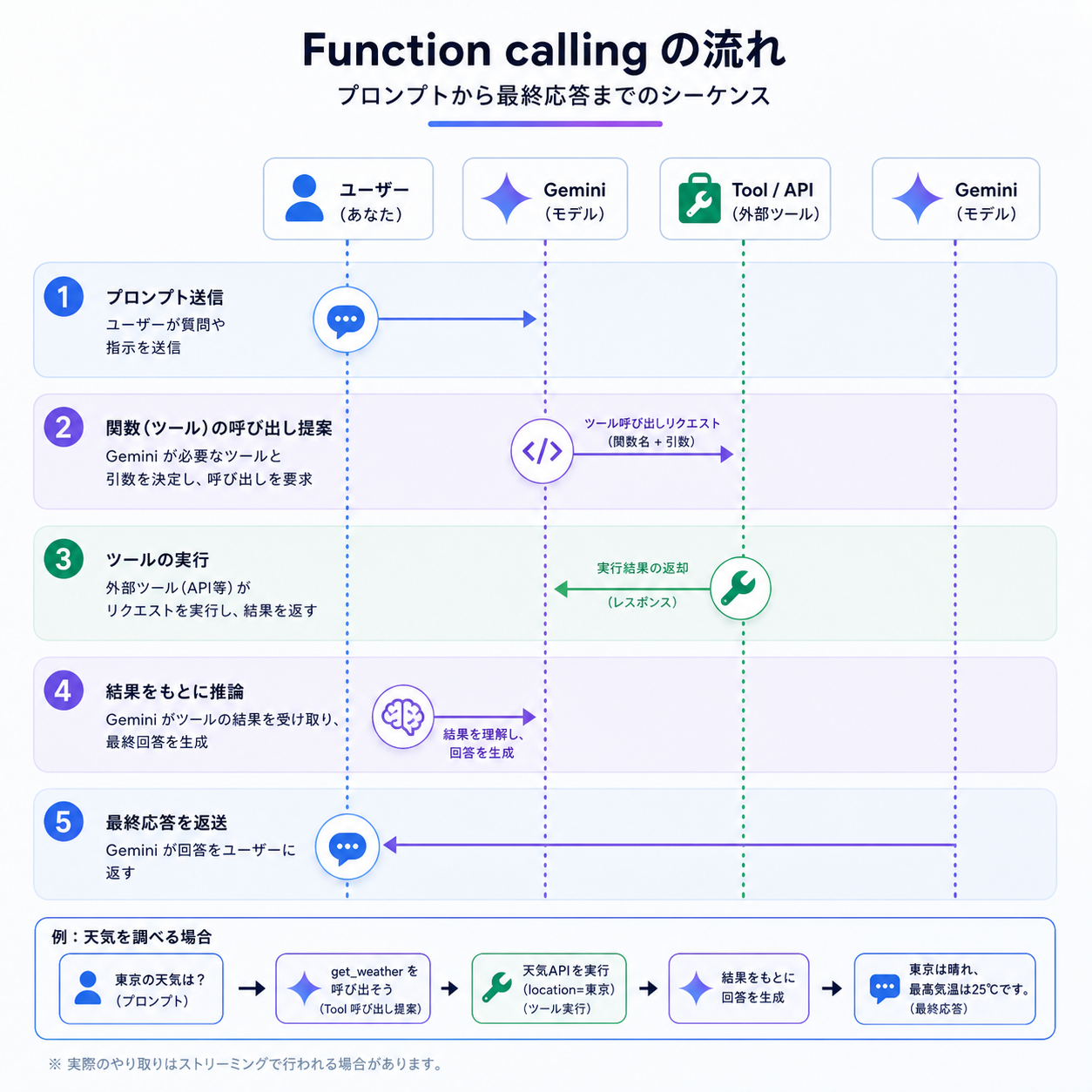
Function callingでは、Pythonの関数をそのままToolとして渡せます。Geminiが必要に応じて関数呼び出しを提案し、SDKが自動で関数を実行して結果をモデルに戻す「自動関数呼び出し」も使えます。
def get_weather(city: str) -> str:
"""指定された都市の現在の天気を返します。"""
# 実際はAPI呼び出し
return f"{city}は晴れ、気温22度です。"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="東京の天気を教えて。",
config=types.GenerateContentConfig(
tools=[get_weather],
),
)
print(response.text)SDKが関数定義(型ヒントとdocstring)からスキーマを自動生成してくれるため、手動でJSONスキーマを書く必要はありません。複雑なツール群を扱う場合は、types.ToolとFunctionDeclarationで明示的に定義するパターンも用意されています。
Google Search連動のGrounding
最新情報を参照したい場合は、Google検索によるグラウンディング機能を使います。google_searchツールを有効にすると、Geminiが必要に応じて検索結果を取り込み、引用付きで応答します。
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="2026年5月時点のGemini 2.5 Proの料金を教えて。",
config=types.GenerateContentConfig(
tools=[types.Tool(google_search=types.GoogleSearch())],
),
)
print(response.text)
# 引用元は response.candidates[0].grounding_metadata から確認可能ニュース要約、相場確認、最新ドキュメント参照といった用途で、自前でWebスクレイピングを書かずに最新情報をモデルに渡せます。引用元のURLが返るので、出典付き回答もそのまま実装できます。
構造化出力(JSONスキーマ)
JSONを確実に得たい場合は、response_mime_typeとresponse_schemaを設定します。PythonのTypedDictやpydanticモデルからスキーマを渡せて便利です。
from pydantic import BaseModel
class Course(BaseModel):
title: str
level: str
hours: int
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Python初心者向けの講座を1つ提案して。",
config=types.GenerateContentConfig(
response_mime_type="application/json",
response_schema=Course,
),
)
course: Course = response.parsed
print(course.title, course.hours)response.parsedで型付きオブジェクトが取り出せるため、後続処理が安定します。Webhookやワークフロー連携で「決まった構造のJSONを返す」要件があるアプリと相性が良い機能です。
ビジョン入力:画像と動画
画像はファイルパスやバイト列、PIL Imageオブジェクトをそのままcontentsに渡せます。動画はFile APIで一度アップロードしてから参照します。
from PIL import Image
img = Image.open("./screenshot.png")
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
"この画面の状態を1段落で説明してください。",
img,
],
)
print(response.text)動画の場合はclient.files.upload(file="meeting.mp4")でアップロードし、戻り値のオブジェクトをcontentsに渡します。会議録画から議事録を作る、製品デモから機能一覧を抽出する、といったユースケースが定番です。
コスト最適化のコツ
- 大量バッチや分類はFlash-Liteを採用し、Proは品質が必要な工程だけに限定する
- 同じシステムプロンプトや長文コンテキストを繰り返し使う場合は、
cachesAPIで明示的なコンテキストキャッシュを利用する max_output_tokensで出力長を上限指定して暴走を防ぐ- SDKの
response.usage_metadataを毎回ログに残し、入出力トークンの実績を監視する - 本番運用ではVertex AI経由に切り替えてリージョン制御・監査ログを整える
Geminiは単価が低いモデルが揃っているため、ナイーブに書いても安く済みやすいですが、長期運用では「FlashとFlash-Liteの使い分け+キャッシュ+出力長制御」を最初から仕込んでおくと、月額の振れ幅を抑えられます。
まとめ
2026年5月時点のGemini APIは、google-genai SDKを使うことでマルチターン、ストリーミング、Function calling、Grounding、構造化出力、ビジョン入力までを少ないコードで扱えます。Flash系の低単価とProの高品質を使い分け、必要に応じてClaude APIや他のLLMと組み合わせると、自分のアプリに最適な構成を作れます。
Gemini APIとAIアプリ開発を学ぶ
Google AI StudioとGemini API、Python×AI開発を実践形式で学べるUdemy講座を公開しています。
