この記事にはアフィリエイトリンクが含まれる場合があります。
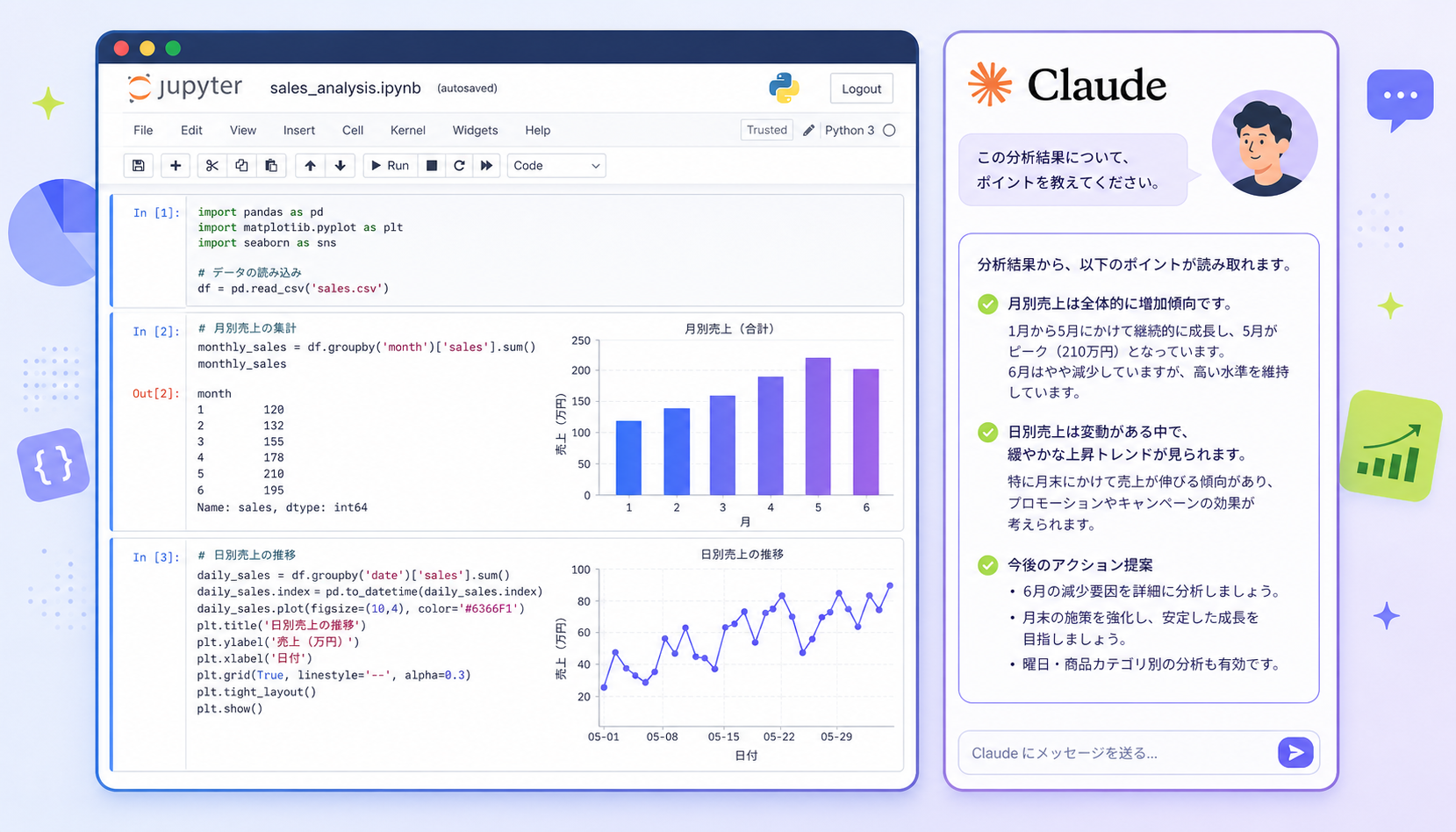
「毎月の売上CSVを集計し、コメント付きレポートとして共有する」という作業は、ほとんどの組織で定型化しているはずです。pandasで集計し、Claude APIにEDAナラティブと改善仮説を語らせ、matplotlibでチャートを描き、Slackや社内ポータルへ流す。この一連の流れは、2026年5月時点のスタックなら数十行のPythonで現実的に組めます。
本記事では、anthropic 0.100.0とClaude Sonnet 4.6を中心に、ノートブック風のサンプルでEDAナラティブ・異常検知・可視化コード生成の3パターンを解説します。同じデータセットへ何度も質問するときのPrompt Caching、数万行を捌くBatch API、深い因果仮説を引き出すAdaptive Thinkingまで、運用前提で触れていきます。
PythonとClaude APIでデータ分析を自動化する全体像
自動化パイプラインは次のステップで構成します。各ステップを独立した関数に分けると、後から差し替えやテストがしやすくなります。
- データソース(CSV / DB / DWH)から取得
- pandasで前処理(型変換、欠損処理、集計)
- 集計結果をClaude Sonnet 4.6へ渡してEDAナラティブと示唆を生成
- matplotlibまたはplotlyで可視化コードを生成・実行
- HTML/PDF/Slackへレポート配信
Claudeは「集計済みの数字を読んで言葉にする」役割が最も得意です。生データを丸投げするより、まずpandasで縮約してから渡したほうが、コストも品質も両立します。
2026年5月のスタック
本記事は次の構成を前提に書きます。料金やモデル仕様はAnthropic PricingとModels overviewを確認した内容です。
- Python 3.11以降
anthropic 0.100.0(2026年5月6日リリース)pandas 2.2系、matplotlib 3.9系- Claude Sonnet 4.6(主役)、Haiku 4.5(分類)、Opus 4.7(複雑な仮説のみ)
python -m pip install -U "anthropic>=0.100.0" pandas matplotlib python-dotenvノートブックでの最小サンプル
まずは月次売上CSVに対する最小構成のEDAコードです。Jupyterで上から実行してください。
# cell 1: 読み込み
import pandas as pd
df = pd.read_csv("sales_2026.csv", parse_dates=["date"])
df["month"] = df["date"].dt.to_period("M")
# cell 2: 集計
monthly = (
df.groupby(["month", "category"])["amount"]
.agg(sum="sum", mean="mean", count="count")
.reset_index()
)
summary = monthly.to_string(index=False)
print(summary[:1000])パターンA:pandasの集計をEDAナラティブとして語らせる

集計済みテーブルを渡し、伸びたカテゴリ・落ちたカテゴリ・季節性の3観点で簡潔に語らせるのが定番です。Claude Sonnet 4.6はテーブル読解と日本語の説明文生成の両方が得意で、毎月のレポートコメントを置き換える用途に向きます。
from anthropic import Anthropic
client = Anthropic()
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="あなたはBIアナリストです。事実に基づき、断定しすぎず、数値根拠を明示します。",
messages=[{
"role": "user",
"content": (
"次の月次×カテゴリ集計表から、伸びた要素・落ちた要素・季節性の3観点で"
"それぞれ2文ずつ日本語コメントを生成してください。\n\n" + summary
),
}],
)
print(resp.content[0].text)Claudeの出力をマークダウンや辞書として返させる場合は、systemに「コードフェンスは付けない」「JSONのみ」など強い制約を入れると後処理が安定します。
パターンB:異常検知と理由解説
pandas側でz-scoreやIQRベースの簡易異常検知をしたあと、検出された行だけClaudeに「なぜ異常か」「業務的に説明できる仮説は何か」を考えさせると、分析者の負担が大きく下がります。
import numpy as np
g = df.groupby("category")["amount"]
df["z"] = (df["amount"] - g.transform("mean")) / g.transform("std")
anomalies = df[df["z"].abs() > 3]
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": (
"次の異常値候補について、考えられる業務的な原因仮説をそれぞれ最大3つ、"
"確認すべきデータと併せて日本語で返してください。\n\n"
+ anomalies.head(20).to_string(index=False)
),
}],
)
print(resp.content[0].text)「事実と仮説を分けて書く」「断定せず確認方法を併記する」とプロンプトに必ず入れます。AIに過信させない設計が重要です。
パターンC:可視化コードの自動生成
Claudeにグラフコードを書かせると、毎月微妙に違うフォーマット要件にも対応しやすくなります。生成コードはサンドボックスで実行し、必ずレビュー後に本番ノートブックへ取り込む運用が安全です。
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="あなたはPython可視化エンジニアです。matplotlibだけを使い、説明文は付けず、コードのみ返します。",
messages=[{
"role": "user",
"content": (
"DataFrame monthly(columns: month, category, sum)から、"
"カテゴリ別の月次推移を1枚の折れ線グラフで描くコードを返してください。"
"凡例は右外、日本語フォントは matplotlib.rcParams で IPAGothic に設定。"
),
}],
)
code = resp.content[0].text同じデータセットを何度も分析するならPrompt Caching
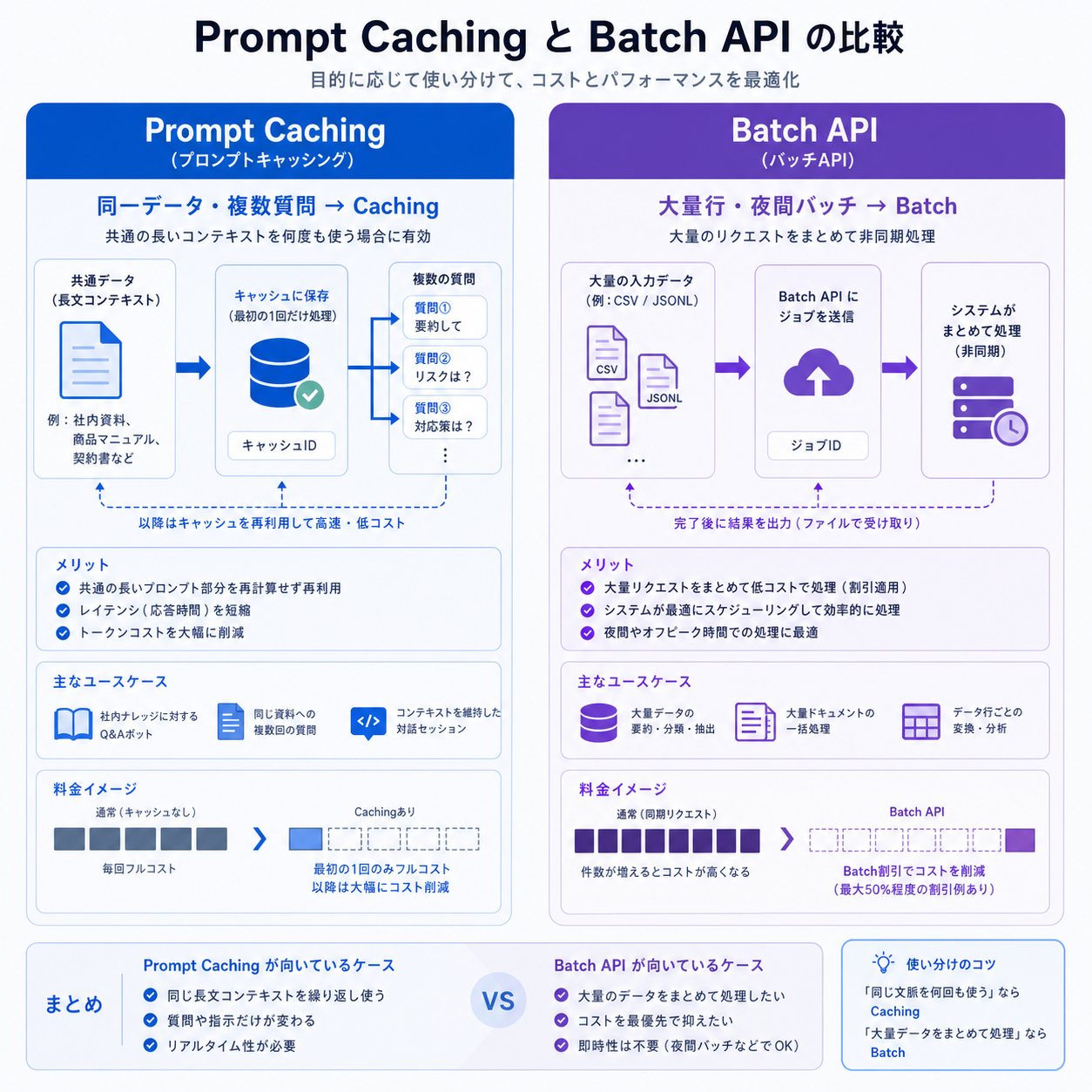
同じ集計表に対して「カテゴリ別」「店舗別」「期間別」と質問を変える場面では、Prompt Cachingで共通コンテキストをキャッシュすると、2回目以降の入力単価が0.1倍まで下がります。Sonnet 4.6の通常入力$3 / MTokなら、キャッシュ読み取りは$0.30 / MTokです。
system_blocks = [
{"type": "text", "text": "あなたはBIアナリストです。"},
{"type": "text", "text": f"対象データ:\n{summary}", "cache_control": {"type": "ephemeral"}},
]
for q in ["伸びたカテゴリは?", "下げ止まりが見える月は?", "在庫を増やすべき品目は?"]:
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
system=system_blocks,
messages=[{"role": "user", "content": q}],
)
print(q, "->", resp.content[0].text[:120])キャッシュのデフォルトTTLは5分、追加コストで1時間TTLも選べます。同一ノートブック内で続けて問い合わせる場合は5分で十分なケースが多いです。
数万行を要約・分類するならBatch API
レビュー文の感情分類、問い合わせカテゴリ判定、商品名のクレンジングなど、行単位で独立した処理はMessage Batches APIが向きます。最大100,000リクエスト・256MBまで、標準価格の50%割引、多くは1時間未満に完了します。
requests = [
{
"custom_id": f"row-{i}",
"params": {
"model": "claude-haiku-4-5",
"max_tokens": 64,
"messages": [{"role": "user", "content": f"次のレビューを positive/neutral/negative で返答: {t}"}],
},
}
for i, t in enumerate(reviews)
]
batch = client.messages.batches.create(requests=requests)結果はclient.messages.batches.results(batch.id)でストリーミング取得し、pandas DataFrameの該当列にマージします。Haiku 4.5+Batchで、数万件のテキスト分類が数百円規模に収まることが多いです。
Adaptive Thinkingで因果仮説まで踏み込む
「なぜ4月の北日本だけ落ちたか」「広告費との相関が崩れた理由」のような踏み込んだ仮説検討では、Adaptive Thinkingを有効にすると推論が深くなります。日次の単純集計には不要ですが、月次レビューで一段深い示唆が欲しいときに使うと費用対効果が高くなります。
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
thinking={"type": "adaptive"},
effort="medium",
messages=[{"role": "user", "content": "4月の北日本売上が前年同月比で落ちた要因を、データ表から仮説を3つ立てて。"}],
)運用上の注意点
顧客名や決済情報を含むデータは、外部APIに送る前に列単位でマスキングします。Claudeが書いた数式やコードは必ず別環境で検算してから本番ノートブックに反映してください。出力にはrequest-idと入出力トークン数をログに残し、月次でコストを振り返ると暴走を防げます。
まとめ
2026年5月のデータ分析自動化は、pandasで縮約し、Claude Sonnet 4.6に語らせ、Haiku 4.5+Batchで量を捌き、Prompt Cachingで反復コストを下げる構成が基本形です。まずは1つの定型レポートを完全置換できる小さなパイプラインを作ると、横展開で大きな時間が浮きます。
PythonとClaude APIでデータ分析を学ぶ
pandasとClaude APIを組み合わせた業務分析自動化を実践形式で学べるUdemy講座を公開しています。
