この記事にはアフィリエイトリンクが含まれる場合があります。
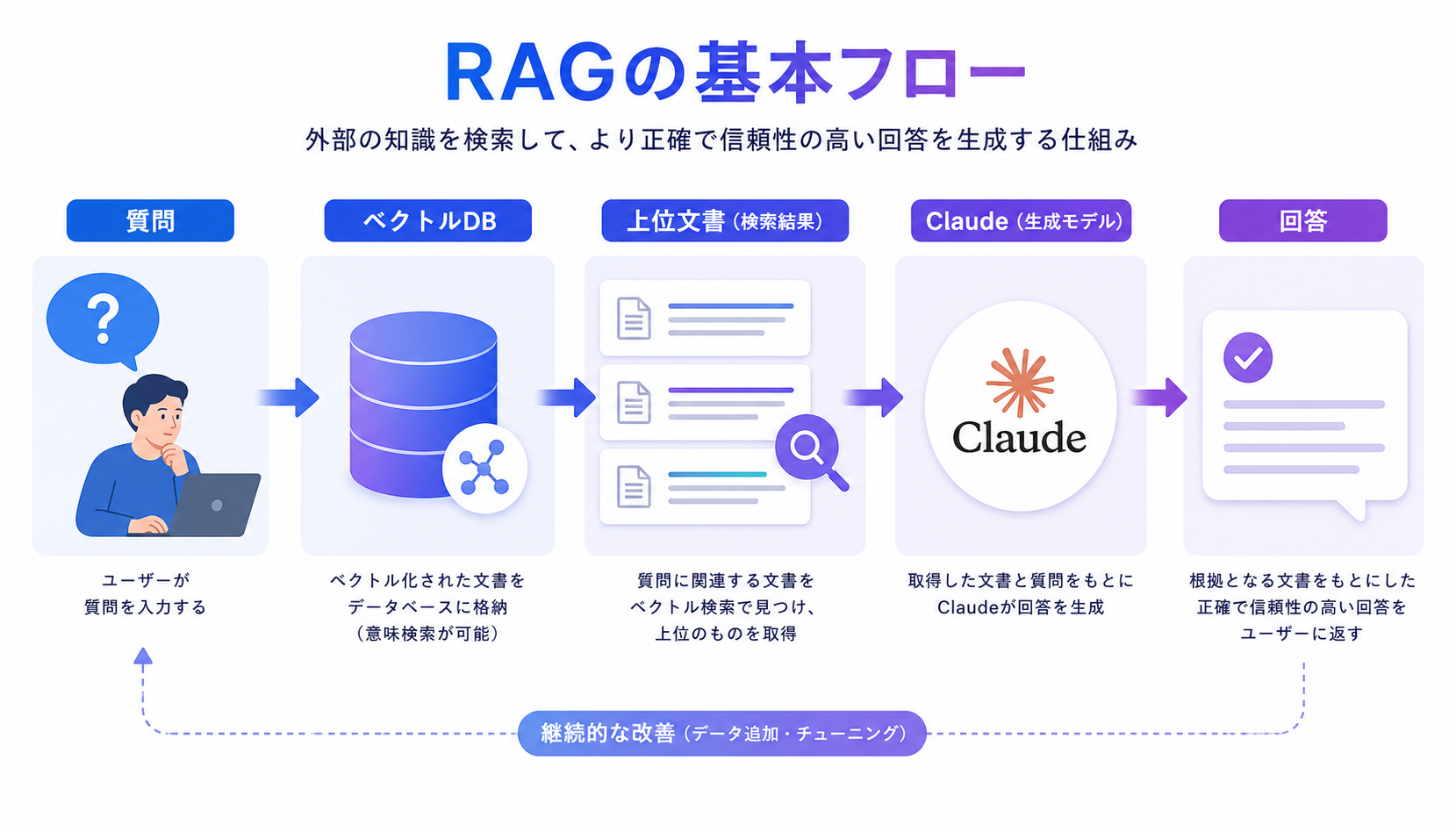
RAG(Retrieval-Augmented Generation:検索拡張生成)は、LLMが学習していない社内ナレッジや最新ドキュメントを、外部検索から取り込んで回答に使う仕組みです。2026年5月時点では、企業内AIアシスタントやサポートボット、社内検索の中核技術として完全に定着しました。
本記事では、RAGの基礎概念から「いつRAGを使うか」「2026年の標準スタック」「Chroma+Claude Sonnet 4.6での最小実装」「ハイブリッド検索+リランキング」「評価の入れ方」までを、実装目線で一気通貫に解説します。Claudeの1Mコンテキストとの使い分けにも踏み込みます。
RAGとは:30秒で理解する
RAGは「質問→関連文書を検索→検索結果と質問をLLMに渡して回答生成」という流れを取る構成です。LLMの内部知識に頼りきらず、検索結果を根拠に答えさせるため、最新情報やプライベートなナレッジに強く、ハルシネーション(事実と異なる回答)を抑えられます。
登場は2020年のMeta AI論文ですが、2026年の実用RAGはハイブリッド検索、リランキング、評価指標の整備によって、初期型から大きく進化しています。素朴な「ベクトル検索だけ」のRAGは2024年頃の常識で、現在は検索精度・出典管理・更新運用までを含めたシステム設計が標準になっています。
本記事は「これからRAGを業務で組む」エンジニアと、「すでに動かしているが品質が伸び悩んでいる」担当者の両方を想定し、現場で踏みやすい落とし穴と改善ポイントを織り交ぜながら解説します。
RAGが必要になる3つの場面
- 最新情報への追随:モデルのカットオフ以降の出来事や、毎日更新されるFAQに回答させたい
- ハルシネーション削減:根拠文書を明示できるため、誤回答を運用上トレースしやすい
- 社内ナレッジ活用:社内マニュアル、規程、過去チケットといった非公開資産を取り込みたい
2026年5月の標準スタック
| レイヤ | 2026年の主流 | 備考 |
|---|---|---|
| Embeddingモデル | OpenAI text-embedding-3-small、Jina jina-embeddings-v3 | 多言語対応、低コスト |
| ベクトルDB | Chroma / Qdrant / pgvector | 小〜中規模はChroma、運用重視はQdrant、既存Postgres流用はpgvector |
| Retriever | ベクトル検索+BM25のハイブリッド | キーワード型クエリの取りこぼし対策 |
| Reranker | Cohere Rerank / Jina Reranker / cross-encoder系 | 上位kから本当に効く文書を選び直す |
| Generator | Claude Sonnet 4.6(1Mコンテキスト) | 長い参考資料を一度に渡しやすい |
| 評価 | Ragas、TruLens、独自スクリプト | faithfulness / context recall / answer relevance |
RAG vs 長コンテキスト vs ファインチューニング
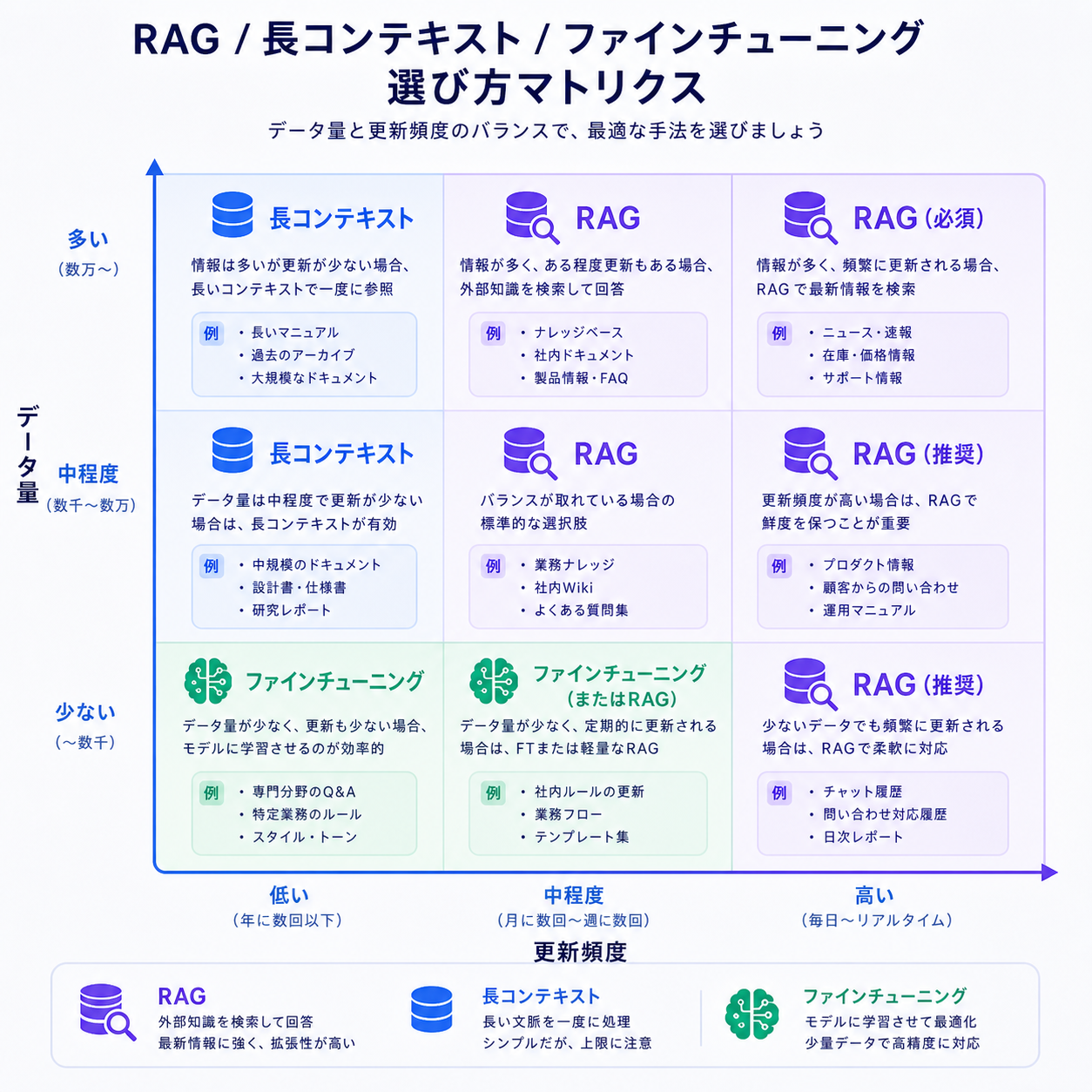
Claude Opus 4.7 / Sonnet 4.6が1Mトークンのコンテキストを持つようになり、「全部プロンプトに突っ込めば良いのでは」という議論が増えました。判断軸は単純です。
- RAG:データが大きい・更新が頻繁・出典明示が必要・コストを抑えたい
- 長コンテキスト:データが数百ページに収まる・更新が少ない・調査タスク向き
- ファインチューニング:振る舞いや文体を恒常的に変えたい・推論を高速化したい
実務では「RAGで検索して上位50チャンクをSonnet 4.6の長コンテキストに丸ごと入れる」というハイブリッド構成が増えています。検索の取りこぼしを長コンテキストで吸収する戦略です。
アーキテクチャ:インデックス時と推論時で分けて考える
RAGの設計は、インデックス時(事前準備)と推論時(質問への回答)を分離して考えると整理しやすくなります。
- インデックス時:文書を取り込み、テキスト抽出 → チャンク分割 → Embedding → ベクトルDBへ格納
- 推論時:質問を受ける → 質問をEmbedding → ベクトルDB検索(+BM25) → Reranker → Claudeへコンテキストとして渡す → 回答生成
チャンクサイズは500〜1000トークン、オーバーラップ50〜150トークンが定番です。表や箇条書きは構造を保ったままチャンクすると検索精度が上がります。Markdownのヘッダ単位や、章節単位など「意味のまとまり」を尊重した分割(semantic chunking)も2026年では一般化しました。
取り込みパイプラインを再実行可能な形で組んでおくと、Embeddingモデルを差し替えたり、チャンク戦略を変えたりするたびに全件再構築でき、検証サイクルが早く回ります。インデックス時の処理をリポジトリ管理しておくのが、長期運用での生命線になります。
最小Python実装(Chroma + Claude Sonnet 4.6)
2026年5月時点の典型的な最小RAGを示します。Embeddingはtext-embedding-3-small、ベクトルDBはChroma、ジェネレータはClaude Sonnet 4.6です。
python -m pip install -U "anthropic>=0.100.0" chromadb openaiimport chromadb, openai
from anthropic import Anthropic
oai = openai.OpenAI()
anthro = Anthropic()
chroma = chromadb.PersistentClient(path="./store")
col = chroma.get_or_create_collection("docs")
def embed(text: str) -> list[float]:
return oai.embeddings.create(model="text-embedding-3-small", input=text).data[0].embedding
# インデックス
docs = ["社内規程: 経費精算は月末締め...", "FAQ: 出張時の宿泊上限は..."]
for i, d in enumerate(docs):
col.add(ids=[str(i)], documents=[d], embeddings=[embed(d)])
# 推論
q = "出張の宿泊費の上限は?"
hits = col.query(query_embeddings=[embed(q)], n_results=4)
context = "\n\n".join(hits["documents"][0])
resp = anthro.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
system="社内規程を根拠に答えます。根拠が無ければ「資料に記載なし」と返します。",
messages=[{"role": "user", "content": f"参考資料:\n{context}\n\n質問: {q}"}],
)
print(resp.content[0].text)本番では取り込み時のメタデータ(出典、章番号、更新日)も格納し、回答に「出典: 規程第3章」のように埋め込むと、レビューと監査が一気に楽になります。
ハイブリッド検索とリランキングで精度を上げる

ベクトル検索だけだと、固有名詞や型番のような完全一致が必要なクエリで取りこぼします。BM25のキーワード検索と組み合わせ、両者の結果をReciprocal Rank Fusionなどで統合する「ハイブリッド検索」が2026年の標準です。
そのうえで、上位30〜50件のチャンクをCohere Rerank、Jina Reranker、または独自のcross-encoderに通し、本当に質問と関連する文書を上位5〜10に絞り込みます。リランカーを噛ませるだけでfaithfulnessが10〜20ポイント上がる事例も多く、最も投資対効果の高い改善ポイントです。
さらに、検索クエリそのものをClaude Haiku 4.5などで前処理してリライト(クエリ拡張)すると、ユーザーの曖昧な質問でも検索ヒットが安定します。「クエリ拡張→ハイブリッド検索→リランキング→Claudeで回答」の4ステップが、2026年5月時点の高品質RAGの黄金パターンです。
評価:faithfulness / context recall を数値化する
RAGは「動いた/動かない」ではなく、精度を数値で見ることが品質保証の出発点です。Ragasなどのライブラリでは以下の指標が使えます。
- faithfulness:回答が検索結果に基づいているか(捏造の少なさ)
- context recall:必要な情報がちゃんと検索できているか
- answer relevance:回答が質問にちゃんと答えているか
20〜50問の評価セットを最初に作り、検索戦略やプロンプトを変えるたびに回す運用が現実的です。評価の自動化にはClaude Opus 4.7のような上位モデルを判定役に使うことが多く、Adaptive Thinkingを有効にすると判定の質が上がります。
よくあるハマりどころ
- PDFのテキスト抽出が崩れている → 抽出方式(pypdf / unstructured / OCR)を見直す
- チャンクが大きすぎて検索ヒットが鈍い → 500〜800トークンに刻む
- 表が壊れて検索精度が落ちる → 表は別チャンクとして構造を保ったまま保存する
- 更新が反映されない → ベクトルDBに版番号メタデータを持たせて差分更新する
- 回答に出典が無く監査できない → ジェネレータプロンプトに「出典名を必ず添える」を明記する
Ragasによる評価とモニタリングの実装
RAGの本番運用で最も足りなくなりがちなのが、継続的な品質モニタリングです。検索パイプラインやプロンプトを変更するたびにスコアが見えないと、改善のつもりが劣化を呼ぶ事故が起きます。2026年5月時点ではPythonのragasライブラリがデファクトで、faithfulness・answer relevancy・context precision・context recallの4指標を一気に計算できます。
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
from datasets import Dataset
# 評価データ:質問、回答、検索コンテキスト、正解(ground truth)
samples = {
"question": [...],
"answer": [...], # RAGの出力
"contexts": [...], # 検索でヒットしたチャンクの配列
"ground_truth": [...], # 期待される回答
}
ds = Dataset.from_dict(samples)
result = evaluate(
ds,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
)
print(result)- faithfulness:回答中の主張が検索contextに裏付けられている割合。捏造の少なさを表す。目標値0.85以上。
- answer relevancy:回答が質問の意図にどれだけ寄り添っているか。脱線や前置きが多いと下がる。
- context precision:上位のチャンクほど質問に関連しているか。リランキングの効きを測る指標。
- context recall:正解を裏付ける情報がコンテキストに揃っているか。検索の取りこぼしを表す。
評価セットは最初は20〜50問でかまいませんが、本番ログから「失敗質問」を継続的にサンプリングして追加するルールを作ると、評価セットがそのまま品質保証の資産になります。CI上でragasを回し、PR時にfaithfulnessが基準を割ったらマージ不可、というガードを入れておくと、プロンプト/検索戦略の改悪を機械的に止められます。LangSmithやArizeなどの観測SaaS、独自のGrafanaダッシュボードとも組み合わせやすく、日次でスコアの時系列を追う運用がそのまま定着します。
ハイブリッド検索チューニングの実例
ハイブリッド検索は「BM25とベクトルを足し合わせるだけ」ではなく、ウェイト調整とRRF(Reciprocal Rank Fusion)の係数次第で精度が大きく動きます。実例ベースのチューニング手順を示します。
def rrf_merge(bm25_hits, vec_hits, k: int = 60, top_k: int = 50):
scores = {}
for rank, doc_id in enumerate(bm25_hits):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)
for rank, doc_id in enumerate(vec_hits):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)
return [d for d, _ in sorted(scores.items(), key=lambda x: -x[1])[:top_k]]- ステップ1:ベースラインの確立。BM25単独、ベクトル単独、RRF統合(k=60)の3パターンで20問評価し、context recallを比較。
- ステップ2:失敗パターンの分類。固有名詞・型番ヒット漏れ → BM25重視。意味検索失敗 → ベクトル重視。混在 → RRF。
- ステップ3:RRF係数kの調整。k=20〜80でグリッドサーチ。kが小さいと上位ランクの影響が強くなり、大きいと全体の合議に近づく。多くの企業ナレッジで最適値はk=40〜60。
- ステップ4:Reranker後段。RRFで上位30件 → Cohere Rerank / Jina Rerankerで上位5〜10へ絞り込み。faithfulnessが10〜20ポイント跳ねるのはこの段階。
- ステップ5:クエリ拡張。Claude Haiku 4.5に質問を3つの言い換えに展開させ、各クエリでハイブリッド検索→結果をRRFで再統合。曖昧な自然文質問の取りこぼしを救う。
実例として、社内FAQ 3,000件のRAGで「BM25のみ」「ベクトルのみ」「RRF k=60」「RRF+Cohere Rerank」「クエリ拡張+RRF+Rerank」を比較したケースでは、context recallが0.62 → 0.71 → 0.79 → 0.88 → 0.93 と段階的に伸びました。faithfulnessも0.74 → 0.79 → 0.82 → 0.91 → 0.94。最初からフル装備を組まず、評価セットを横軸にして1段ずつ足しながら数字を見せる進め方が、ステークホルダー説明にも有効です。改善の優先順位を「数字で示せる」状態を作るのが、RAGプロジェクトを長く回すコツです。
まとめ
2026年5月のRAGは、Embedding+ベクトルDB+ハイブリッド検索+Reranker+Claude Sonnet 4.6という構成が標準形になりました。データ規模や更新頻度に応じて、RAG・長コンテキスト・ファインチューニングを使い分けつつ、評価指標を最初から組み込むことが品質の出発点になります。まずは数十文書の小さなコーパスから始め、評価セットを育てながらスタックを段階的に拡張するのが堅実な進め方です。
RAGとClaude APIを体系的に学ぶ
社内ナレッジを活かしたRAGアプリ開発を実践形式で学べるUdemy講座を公開しています。
